


HDF5(Hierarchical Data Format version 5)は、巨大なデータセットや複雑なデータ構造を効率的に管理・格納するためのファイルフォーマットであり、バイオインフォマティクス分野においても非常に有用です。
本記事では、HDF5ファイルのフォーマットおよびPythonライブラリのh5pyを用いてHDF5ファイルを作成・操作する具体的な方法について解説します。
HDF5形式とは
HDF5 (Hierarchical Data Format version 5) は、以下のような特徴を持つデータ保存フォーマットです。
-
階層構造: ファイル内はフォルダに似た「グループ」と、実際のデータが格納される「データセット」に分かれており、ツリー状の構造で管理されます。
-
大規模データの扱い: 数十ギガバイト以上の巨大データでも高速に読み書きが可能です。
-
柔軟性: さまざまなデータタイプ(数値データ、文字列、画像など)を統一フォーマットで保存でき、科学計算や機械学習の分野で広く利用されています。
HDF5形式は、実験データやシミュレーション結果などの保存に適しており、特にシングルセル解析では、10x Genomics などのプラットフォームから出力されるデータファイルとして採用されています。
高速な入出力と大規模データの管理
-
次世代シーケンシング(NGS)のデータ
バイオインフォマティクスでは、シーケンシングやマイクロアレイ実験などにより、数十GBに及ぶデータが生じることがあります。HDF5は部分的なデータ読み書きが可能なため、巨大データの中から必要な部分だけを高速に取り出すことが可能です。 -
階層構造によるデータ整理
データを「グループ」や「データセット」という階層構造で整理できるため、ゲノム情報、アライメント結果、メタデータ、解析パラメータなど、異なる種類のデータをひとつのファイルに効率よく格納できます。 -
圧縮と効率的なストレージ
HDF5は内部でのデータ圧縮にも対応しており、ディスク容量の削減とI/O負荷の軽減を実現できます。
これらの特性から、HDF5は大規模かつ多様なバイオインフォマティクスデータの管理・解析に適していると考えられます。
h5pyの使い方
Pythonでは、HDF5ファイルの読み込みに h5py ライブラリを用います。組み込みでインストールされているので、特別にインストールすることなく使うことができます。
HDF5ファイルの作成
h5pyを用いて、簡単なHDF5ファイルを作成してみます。
with h5py.File('example.h5', 'w') as h5file:
# グループを作成
group = h5file.create_group('genomics_data')
# グループ内にデータセットを作成
group.create_dataset('expression_matrix', data=np.random.rand(50, 50))
# 別のデータセットをルートに作成
h5file.create_dataset('sample_info', data=np.array([1, 2, 3, 4]))withブロック内でファイルを開くことで、ブロックを抜ける際に自動的にファイルがクローズされ、リソース管理も容易になります。このように、グループを利用することでデータの構造化が可能となり、後の解析やデータ抽出時に効率が向上します。また、create_datasetメソッドは、データを渡すと同時にデータセットを作成し、内部で自動的に型や形状を認識して設定します。
HDF5ファイルの読み込み
次に、先ほど作成したHDF5ファイルを読み込んで中身を確認するとともに、中身を少し編集してみます。
# 書き込んだファイルの読み込み
with h5py.File('example.h5', 'r+') as h5file:
# ルート直下の 'sample_info' データセットを読み込み
sample_info = h5file['sample_info'][:]
print("Sample Info:", sample_info)
# グループ 'genomics_data' 内の 'expression_matrix' にアクセス
expr_matrix = h5file['genomics_data/expression_matrix']
print("Shape of Expression Matrix:", expr_matrix.shape)
# 例として、'expression_matrix' の先頭要素を変更
expr_matrix[0, 0] = 42.0このコードでは、読み込みモードを 'r+'(読み書き可能)でファイルをオープンしており、既存のデータセットに対する変更も反映させています。なお、[:] というスライシングを使うことで、データセット全体をNumPy配列として取り出すことができます。
属性(Attributes)の設定
データセットやグループには、メタデータとして属性を付与することができます。これにより、各データの説明や解析時のパラメータを一緒に保存できます。
with h5py.File('example.h5', 'w') as h5file:
dset = h5file.create_dataset('dataset_with_attr', data=np.arange(10))
# 属性の設定
dset.attrs['description'] = 'This is a sample dataset'
dset.attrs['version'] = 1.0属性を利用することで、データの意味を明示的に記録でき、後からデータを扱う際の理解が進みます。
10xGenomicsのHDF5ファイル形式での実践
10x Genomicsの出力ファイル(特に Cell Ranger による解析結果として得られる filtered_feature_bc_matrix.h5 や raw_feature_bc_matrix.h5)は、HDF5フォーマットの強みを生かして、single cell RNA-seq(scRNA-seq)の大規模かつ疎なマトリクス表現や、対応するメタデータを階層的に格納できるよう設計されています。
10x Genomicsの出力ファイルの構造は下記のようになっています。

以下の主要なコンポーネントに分かれています。
matrix グループ
-
matrix グループ
このグループには、実際のカウント情報を表現する疎行列が格納されています。具体的には、CSC(Compressed Sparse Column)方式に基づいて保存されており、次の要素が含まれます:-
data
ゼロでないカウント値(整数や浮動小数点数)が 1 次元配列として格納されています。 -
indices
各カウント値がどのフィーチャ(行)に属するかを示すインデックス情報。 -
indptr
各細胞(列)の開始位置を示すポインタ。これにより、細胞ごとの発現カウントデータの位置を高速に特定できます。 -
shape
マトリクス全体のサイズ(フィーチャ数 × 細胞数)を示す情報。 - barcodes
このデータセットには、各細胞を一意に識別するバーコードが保存されています。バーコードの順序は、マトリクス内の列の並びと一致しており、後続の解析で細胞ごとにデータを関連付ける際に重要な役割を果たします。
-
この構造により、大部分がゼロとなる疎なデータでも、必要な情報のみを効率的に保存・アクセスできるようになっています。
featuresグループ
-
features
ここには、各行に対応するフィーチャ(遺伝子やその他の分子)が格納されています。具体的な項目としては:-
id
例:Ensembl ID など、フィーチャを一意に識別するための識別子。 -
name
ヒトの場合、遺伝子シンボルや名称などの情報。 -
feature_type
フィーチャの種類(例:タンパク質コード遺伝子、非コードRNA、アクセシブル領域など)で、解析やフィルタリングに利用される。
-
これらの情報は、従来のテキスト形式(例えば、genes.tsv)と同様に、フィーチャの意味付けや下流でのアノテーションに使用されます。
公共データのダウンロード
実践データとして、GSE293707として公開されているデータセットを使用します。この研究では、COVID-19患者のT細胞におけるCD55発現上昇とI型インターフェロン応答抑制のメカニズムについて、scRNA-seqデータをもとに解析がおこなわれています。
https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE293707
下部のDownloadのcustomを開き、Supplementary fileの.h5ファイルをダウンロードします。
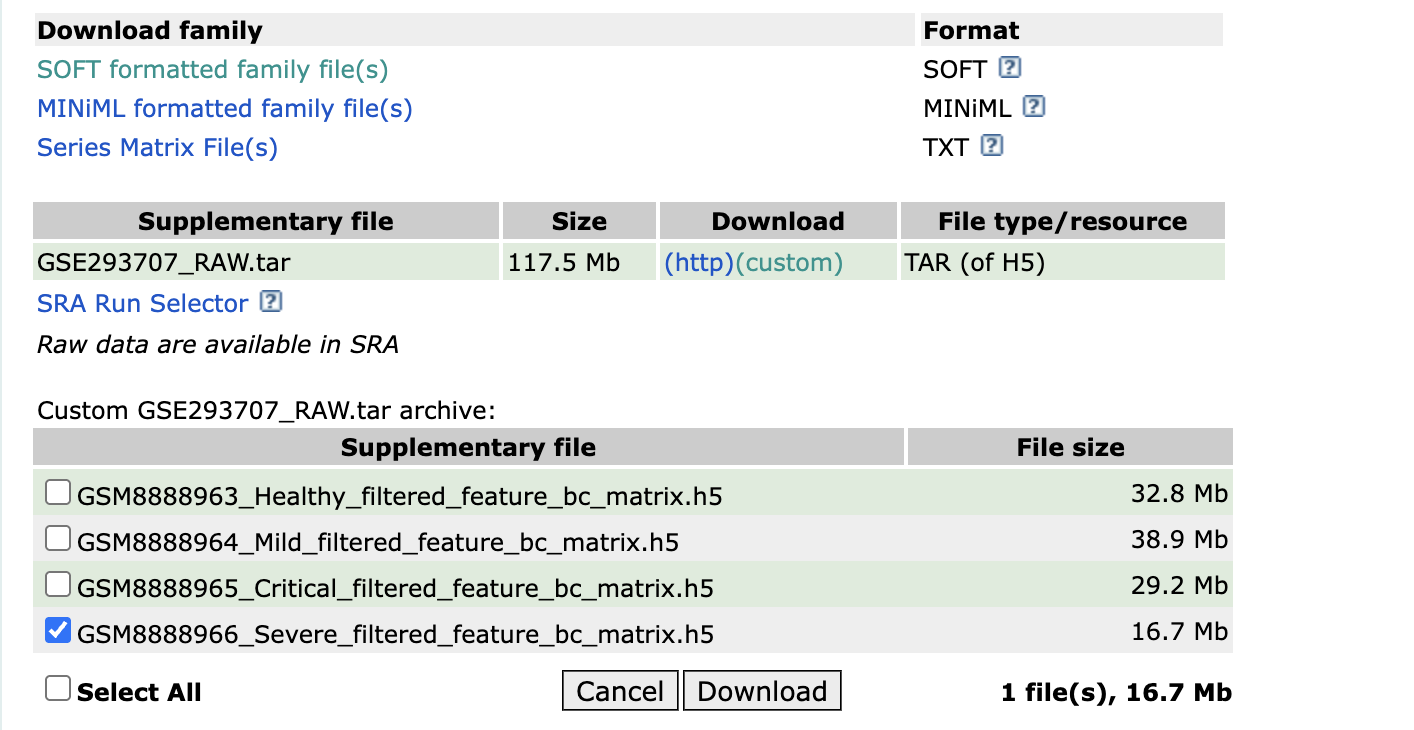
ダウンロードすると、GSE293707_RAW.tarとしてアーカイブされた形でダウンロードされますが、そのままで読みこめるので、読みこんで内容を確認してみます。
with h5py.File("./GSE293707_RAW.tar", "r") as h5file:
print(h5file.keys())<KeysViewHDF5 [‘matrix’]>が出力され、matrixというグループが存在することがわかります。
matrixグループの中を確認してみます。
with h5py.File("./GSE293707_RAW.tar", "r") ash5file:
# matrixグループの内容を表示
for key in h5file["matrix"].keys():
print(h5file["matrix"][key])<HDF5 dataset "barcodes": shape (7966,), type "|S18">
<HDF5 dataset "data": shape (11564181,), type "<i4">
<HDF5 group "/matrix/features" (5 members)>
<HDF5 dataset "indices": shape (11564181,), type "<i8">
<HDF5 dataset "indptr": shape (7967,), type "<i8">
<HDF5 dataset "shape": shape (2,), type "<i4">確かに、barcodes, data, indices, indptr, shape, featuresなどがデータとして存在することを確認することができました。
まとめ
本記事では、HDF5ファイルのフォーマットおよびPythonライブラリのh5pyを用いてHDF5ファイルを作成・操作する具体的な方法について解説します。
HDF5ファイルは、テキストファイルとは違って簡単に中身を確認することができないため、戸惑うことがあると思いますが、h5pyのようなツールを用いることで操作可能になります。
ぜひ、様々なデータを確認してみてください。






